1) a) Briefly describe how does k-means clustering algorithm work?
b) What type of learning algorithm is K-means clustering? (supervised/ unsupervised/ semisupervised)
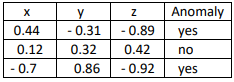
2) The following table consists of training data from an accelerometer database (x, y, z). Let anomaly be the class label attribute. Design a feed-forward neural network with one hidden layer for the given data. Label the nodes in the input and output layers.
3) The following table consists of training data from an employee database. The data have been generalized. For example, “31 . . . 35” for age represents the age range of 31 to 35. For a given row entry, count represents the number of data tuples having the values for department, status, age, and salary given in that row.
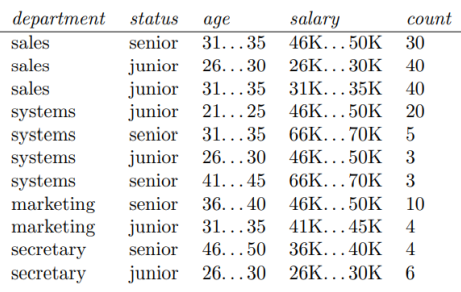
Let status be the class label attribute. Given a data tuple having the values “Sales”, “31. . . 35”, and “31K–35K” for the attributes department, age, and salary, respectively, what would a naive Bayesian classification of the status for the tuple be? Show enough work to convince me that you are using the algorithm and that your answer isn’t just a guess.
Please write R code for problem 4 ( problem4.R ) using RStudio
4) Iris is a built-in dataset that comes with R. It contains 150 observations of flowers from 3 different types of iris species.
Load Iris dataset and select only the first four columns into your data-frame and name it “data”. Implement K-means clustering algorithm with k=3 on your data.
a) Print the location of each centroid.
b) Plot your clusters graph.
Students succeed in their courses by connecting and communicating with an expert until they receive help on their questions

Consult our trusted tutors.








 Login | Sign Up
Login | Sign Up

