Question 1. How and why regression analysis may contribute to managerial decision making? Explain in general and provide examples.
Question 2. What might be the limitations of linear regression application in business research? Why?
Case 1.
The manager of the beer concession at a major league baseball stadium wants to be able to predict the amount of beer sold during a baseball game. In recent years, the team has been very successful, so in most games the attendance has been quite close to capacity. The manager believes that the most important variable in predicting beer sales is the temperature. He feels that the higher the temperature, the greater the number of beers ordered will be. However, the relationship is not likely to be linear, since there should not be much difference between 90° and 100°F. He proposes the second-order model.
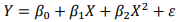
where Y = Number of beers sold
and X = temperature (in degrees Fahrenheit).
To test his belief the manager selects 50 days at random when the team played at home and records the number of beers sold (in the thousands) and the mean temperature during the game (see Table 1, MODEL1).
The owner of the beer concession believes that he can improve the predictive power of the model if he includes the winning percentage of the visiting team. According to his logic, a visiting team that is quite good will increase the enjoyment and excitement of the game, resulting in more beers sold. So he proposes the first-order model with two variables.
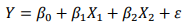
where
X1 = Temperature and
X2 = Visiting team winning percentage.
Using the same 50 days the owner obtained the results shown in Table 1 (MODEL 2). Then he decided to make the model better and included a dummy variable for a TV announces of each game (D=1 if there was an announcement before the game and D=0 if there was no announcement). So he proposes the first-order model with three variables.
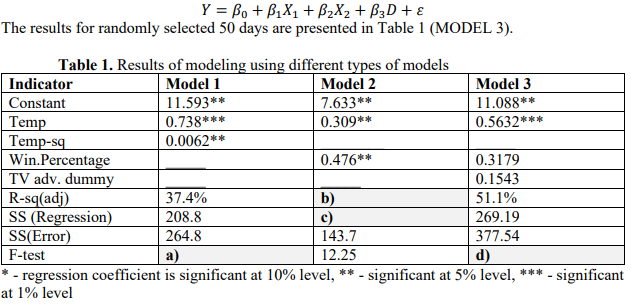
Question 3. Calculate necessary values mentioned in a), b), c) and d). Explain the model’s utility and statistical significance for each model from a table supporting explanations with data.
Question 4. Write down three regression equations prepared to estimate the models. Suppose the owner decided to predict the number of beer sold for the next game. Which model is better to use for this purpose and why?
Question 5. List the OLS assumptions. Are they met for the best model? Explain.
Case 2.
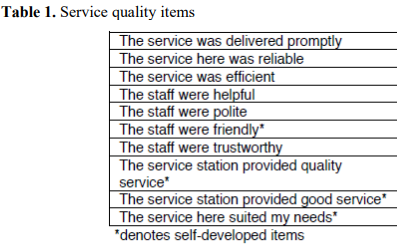
Examination of the service quality literature defines service quality as an overall appraisal of a product or service that is dependent on consumers’ prior expectations (Grönroos, 1984; Bitner & Hubbert, 1994). In order to continue this line of research, the authors decide to examine whether a two-dimensional model of service quality would fit a dataset on service stations including 355 observations. In this dataset, service quality was measured using items developed by Grace and O’Cass (2004) as well as several self-developed items. The items are presented in Table 1 below. All items were measured using 7-point scales anchored with ‘strongly disagree’ (1) and ‘strongly agree’ (7).
Tables 2 and 3 present the results of a factor analysis on the data.
Table 2. Total variance explained
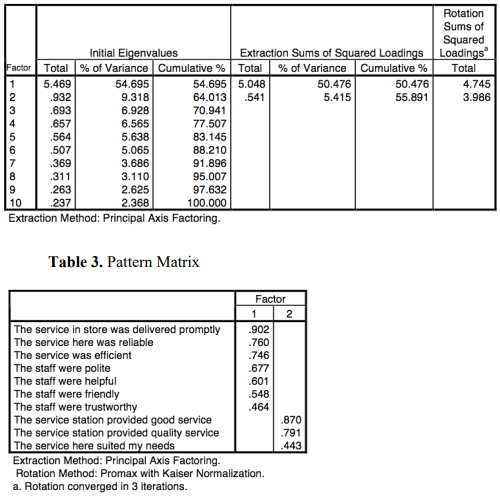
Question 6. Based on the Jolliffe’s eigenvalue criterion, how many factors would you extract? Interpret the factors and the factor loadings presented in Table 3. To continue with the analysis, the authors decide to investigate the perceived impact of service quality on the average weekly number of calls to the center. Two strategies are considered:
Strategy 1. To forget about the factor analysis and to develop a multiple regression model based on the initial variables presented in Table 1.
Strategy 2. To use factor analysis first and run a regression analysis based on the factors instead of the initial variables in Table 1.
Discuss the advantages and limitations related to both approaches described above.
Students succeed in their courses by connecting and communicating with an expert until they receive help on their questions

Consult our trusted tutors.








 Login | Sign Up
Login | Sign Up

