Pass Task 7.1P: K-Means and Hierarchical Clustering
Task description:
In machine learning, clustering is used for analyzing and grouping data which does not include pre-labelled class or even a class attribute at all. K-Means clustering and hierarchical clustering are all unsupervised learning algorithms.
K- means is a collection of objects which are “similar” between them and are “dissimilar” to the objects belonging to other clusters. It is a division of objects into clusters such that each object is in exactly one cluster, not several.
In Hierarchical clustering, clusters have a tree like structure or a parent child relationship. Here, the two most similar clusters are combined together and continue to combine until all objects are in the same cluster.
In this task, you use K-Means and Agglomerative Hierarchical algorithms to cluster a synthetic dataset and compare their difference.
You are given:
• np.random.seed(0)
• make_blobs class with input:
o n_samples: 200
o centers: [3,2], [6, 4], [10, 5]
o cluster_std: 0.9
• KMeans() function with setting: init = "k-means++", n_clusters = 3, n_init = 12
• AgglomerativeClustering() function with setting: n_clusters = 3, linkage = 'average'
• Other settings of your choice
You are asked to:
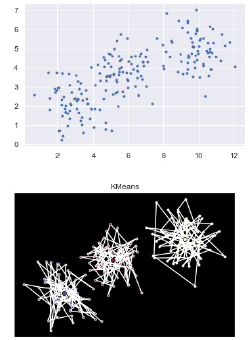
• plot your created dataset
• plot the two clustering models for your created dataset
• set the K-Mean plot with title “KMeans”
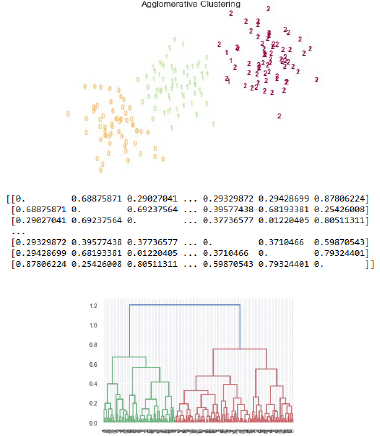
• set the Agglomerative Hierarchical plot with title “Agglomerative Hierarchical”
• calculate distance matrix for Agglomerative Clustering using the input feature matrix (linkage = complete)
• display dendrogram
Sample output as shown in the following figure is for demonstration purposes only. Yours might be different from the provided.
Students succeed in their courses by connecting and communicating with an expert until they receive help on their questions

Consult our trusted tutors.








 Login | Sign Up
Login | Sign Up

