

 Login | Sign Up
Login | Sign UpStatistics
Correlation
Share




What is Correlation
Correlation measures the strength of linear relationship between two variables. Here two variables are measured on ratio scale of measurement. The formula of the correlation coefficient is given by:

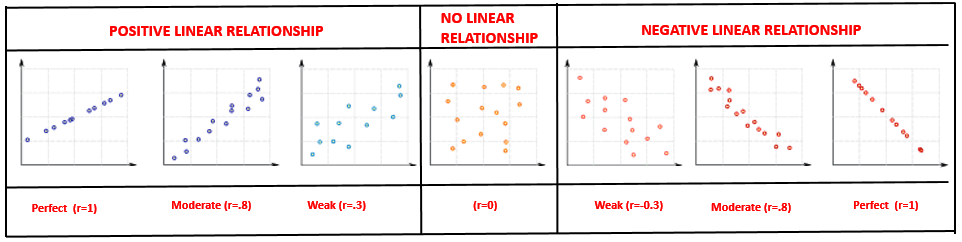
- correlation coefficient between [.7, 1] implies a strong positive linear relationship
- correlation coefficient between [.5, .7] implies a moderate positive linear relationship
- correlation coefficient between [.3, .5] implies a weak positive linear relationship
- correlation coefficient between [-.2, .2] implies no linear relationship
- correlation coefficient between [-1, -.7] implies a strong negative linear relationship
- correlation coefficient between [-.7, -.5] implies a moderate negative linear relationship
- correlation coefficient between [-.3, -.5] implies a weak negative linear relationship
Types of Correlation Coefficient
There a various type of correlation on basis of measurement of the scale of two variable.
| X | Y | Type of Correlation |
| Nominal | Nominal | Phi Coefficient |
| Nominal | Ordinal | Rank bi-serial Coefficient |
| Nominal | Interval | Point Bi-serial Coefficient |
| Ordinal | Ordinal | Spear-man Rank Correlation Coefficient |
| Interval | Interval | Pearson Product moment Correlation Coefficient |
t test for test the significance of Correlation Coefficient
Hypothesis
- Ho1: correlation coefficient is not significant.
- Ha1: correlation coefficient is significant. (Two tailed test)
- Ha2: correlation coefficient is negative. (Left tailed test)
- Ha3: correlation coefficient is positive. (Right tailed test)
Test Statistic

Critical value
- -t(a/2,n-2), t(a/2,n-2) (Two tailed test)
- -t(a,n-2) (Left tailed test)
- t(a,n-2) (Right tailed test)
P-value
- 2*(1-P(T≤|t|) (Two-tailed test)
- P(T≤t) (Left tailed test)
- P(T≥t) (Right tailed test)
Decision rule
- Reject Ho if |t| > t(a/2, df) or p-value < alpha (two-tailed test)
- Reject Ho if –t < -t(a, df) or p-value < alpha (left tailed test)
- Reject Ho if t > t(a, df) or p-value < alpha (right tailed test)
Does Correlation imply Causation?
Correlation doesn’t necessarily imply causation. Correlation measures the degree of association between the two variables. Or in other words, it measures the strength of linear relationship between them. The value of correlation coefficient can lie in the interval [-1, 1]. -1 denotes a perfect negative linear relationship and +1 a perfect positive linear relationship. Values between [-0.3, 0.3] imply a very weak linear association or almost no linear relationship between the two variables. Values between [-0.7, -1] and [0.7, 1] indicates a strong linear relationship. Causation means the change in one variable is caused by other. While correlation depicts the strength of association. Positive linear relationship implies that with an increase in one variable, another variable also increases. Negative linear relationship implies that with increase in one variable, another variable decreases.
Considering two variables cigarettes and pulse rate which are highly correlated, I cannot say Cigarettes alone causes pulse rate to increase, but I am sure that there is a positive linear relationship between the two. That is as the number of cigarettes increases, the pulse rate also increases. And vice versa. There are other possible factors which cause pulse rate to increase. And the association between these variables doesn’t imply causation in statistical terms.
Covariance
Share
What is Co-variance ?
Co-variance measures how two variables are related. A positive value of co-variance implies that two variables are positively related, that is they move together in the same direction. And a negative value of co-variance implies that variables are negatively related, that is they move together in opposite direction. The range of co-variance lies outside the range of correlation. The formula for calculation of Co-variance is given below.

Properties of Co-variance

Regression Analysis
Share
Regression Analysis
Regression analysis is the technique which is widely used for prediction and forecasting. It is basically used to know that dependent variable is related to which independent variable. Linear regression is used to estimate the relationships between variables by fitting an equation to given data. Linear Regression is used to predict the value of y which is dependent on x (explanatory variable or independent). If we consider one independent variable it is referred to as Linear Regression. While if we consider more than one independent variable it is referred to as Multiple Linear Regression models.
The equation of Linear Regression is


With a unit increase in Xi there is βi unit increase/decrease in Y
Hypothesis test of ModelNull Hypothesis: Hoi: Model is not significant.
V/s Alternative Hypothesis: H1i: Model is significant. I use F test statistic to test this.
If p-value < alpha, I reject Ho at 5% level of significance otherwise I fail to reject it.
Hypothesis test of slopeNull Hypothesis: Hoi: βi=0, βi is not significant, i.e. Xi should be included in the model.
V/s Alternative Hypothesis: H1i: βi≠0, βi is significant, i.e. Xi should not be included in the model.
If p-value < alpha, I reject Hoi at 5% level of significance otherwise I fail to reject it.
The confidence interval of Slope
The confidence interval and Prediction IntervalA confidence interval for an average expected value of y, E(y), for a given x* is given by:
_CI.PNG)
The prediction interval for the average expected value of y, E(y), for a given x* is given by:
_PI.PNG)
Adjusted R2 and Coefficient of Determination (R2)
Adjusted R^2 gives the percentage of variation in dependent variable which is explained by significant independent variables. Adjusted R^2 increases with the addition of significant variables. The formula for adjusted R^2 is given by:
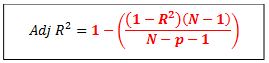
The coefficient of determination, R^2 gives the percentage of variation in dependent variable which is explained by all independent variables in the model. The formula for R^2 is given by:

Step-wise Regression Analysis
Step-wise regression is a semi-automated process of building a model by successively adding or removing variables based solely on the t-statistics of their estimated coefficients. The adjusted R-squared compares the explanatory power of regression models that contain different numbers of predictors. The adjusted R-squared increases only if the new term improves the model more than would be expected by chance. It decreases when a predictor improves the model by less than expected by chance. It is always lower than the R-squared.
What is Multi-co-linearity?
Co-linearity (or multi-co-linearity) is the undesirable situation where the correlations among the independent variables are strong. Multi-co-linearity increases the standard errors of the coefficients. Increased standard errors mean that coefficients for some independent variables may be found not to be significantly different from 0, whereas without multi-co-linearity and with lower standard errors, these same coefficients might have been found to be significant. Thus, it makes some variables statistically insignificant while they should be otherwise significant.
Variance inflation factors (VIF) measure how much the variance of the estimated coefficients is increased over the case of no correlation among the independent variables. If no two independent variables are correlated, then all the VIF's will be 1. If VIF for one of the variables is greater than 3.3, there is Co-linearity associated with that variable.
What are the assumptions of Regression Analysis?
The regression model is easy to use and apply but the major limitation is that regression will give correct results only if dependent and independent variables are correlated to each other.
- One of the assumptions is regression model should not have multi-co-linearity, which means independent variables will not be correlated to each other
- Other assumptions involve there should be no auto-correlation, that is error terms in prediction must not be correlated with each other.
- The variance of error terms must be constant, that there should not be hetero-scedasticity.
- Residuals should be normally distributed.
All these assumptions may not be valid on real-world data which makes it difficult for managers to make a prediction as per regression.





