Q1. Confusion Matrix
Table 1 is a confusion matrix generated by Model A. The notations p and n represent the actual positive and negative. The rows Y and N represent predicted decisions “Yes (Offer)” and “No (No offer)” generated by Model A. There are 100,000 observations in total.
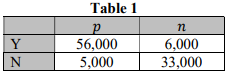
Suppose that the correct positive prediction, i.e. predict Y for p, yields $5, and incorrect positive prediction, i.e. Y for n, yields -$1. No loss nor benefit for negative predictions, i.e. the benefit or cost for predicting an N for p and n is $0.
(a) Calculate the overall expected value for Model A per person. Show the calculation steps and state your answer.
(b) Write down the confusion matrix for the majority model. Majority model is either an “AllNo model” if n is the majority or “All-Yes model” if p is the majority.
(c) Calculate the overall expected value for the majority model per person. Show the calculation steps and state your answer.
(d) Assume same number of Y offers as in Table 1. Write down the confusion matrix for the random model. (e) Calculate the expected overall profit for the random model per person. Show the calculation steps and state your answer.
Q2. k-Nearest-Neighbors
You sell IT products and are using kNN to build an IT wallet estimation predictor. You have information on the total IT budgets of a large set of companies, that will be your database of potential neighbors. You already have decided to use Euclidian distance. Now you want to estimate your wallet share for Acme Corp., one of your current customers for whom you do not know the IT budget. Explain precisely how you will estimate your wallet share for Acme with this technique including (a) stating the target variable, (b) proposing 3 features for predicting the target variable, (c) restriction on the choice of k and (d) evaluation.
Q3. Visualization Curves
A population of 100,000 customers with 2 types p (respond) and n (not respond) has an unbalanced data structure with (p, n) = (25000,75000). The overall response rate is 25%. A predictive model ranks the probability scores of the customers in descending order as shown in Table 2.
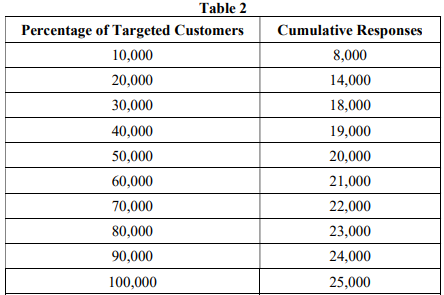
(a) Plot the cumulative response curve at these 10 points with their corresponding (x, y) coordinates, the axis-label and the title of the plot.
(b) Plot the lift curve at these 10 points with their corresponding (x, y) coordinates, the axislabel and the title of the plot.
(c) The cost of each incentive offer is $12. The marketing campaign is subject to a budget constraint of $240,000. How many customers can the firm target?
(d) Suppose the revenue of each customer response is $40 and the cost of each incentive offer is $12. Write down the cost-benefit matrix.
(e) Based on (d), calculate the expected profit per offer? Note: profit=revenue-cost.
Q4. Naive Bayes
Table 3(a) shows the feature “Weather” and decision “play” of 14 instances. The frequency table is summarized in Table 3(b).
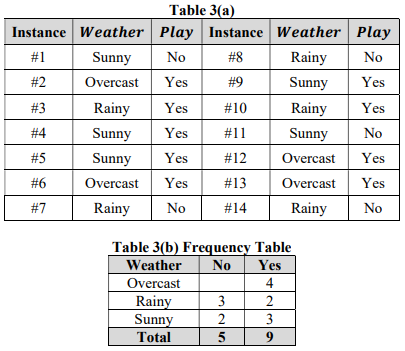
(a) Using Table 3(b) to calculate the marginal likelihood for each type of the weather, i.e. P(Overcast), P(Rainy) and P(Sunny).
(b) Using Table 3(b) to calculate the marginal likelihood for each decision, i.e. P(No) and P(Yes).
(c) Calculate the conditional probability P(Yes|Sunny) using Bayes’ rule.
Q5. Text Mining
Consider two documents d1 and d2. Either of these contains the word “Hello” or “World” as shown in Table 4.
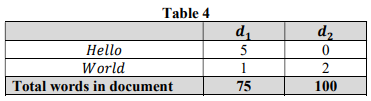
Suppose there are 10,000 documents in the entire corpus and the word “Hello” appears in 4,000 of these documents and “World” in 1000 of these documents.
(a) Calculate the four normalized term frequencies (TF) for “Hello” and “World” in d1 and d2.
(b) Calculate the inverse document frequency (IDF) for these two words.
(c) Calculate the four TF-IDF (i) TF-IDF(“Hello”,d1), (ii) TF-IDF(“World”,d1), (iii) TFIDF(“Hello”,d2), and (iv) TF-IDF(“World”,d2).
(d) Now we have a new query “Hello World”. Calculate the cosine similarity with d1 and d2 respectively. Which one is more similar to the search query?
Students succeed in their courses by connecting and communicating with an expert until they receive help on their questions

Consult our trusted tutors.








 Login | Sign Up
Login | Sign Up

