Background
Networked SIR Model
There are several well-known epidemic models, but the one that we will focus on in this assignment is the (Networked) SIR model. The SIR epidemic model assumes each individual has three states - Susceptible (S) to the disease, Infected (I) by the disease and Recovered (R) to the disease. The progression of states is assumed to be susceptible (S) to Infected (I) to Recovered (R). Initially some in the initial population are infected and all others are susceptible. Once recovered, an individual has immunity and will not be further infected. There are also other models, like SIS (Susceptible, Infected, Susceptible), but for the purpose of this assignment, we will stick with the most fundamental model, the SIR model, as others are really variations on this.
In the traditional SIR model, there is assumption of full mixing between individuals - i.e., any individual can potentially infect another. The model then derives differential equations that estimates the changes in the total number of susceptible, infected and recovered individuals over time, and these are proportional to the numbers of the other two states - e.g., change in number of infected individuals is dependent on the number of susceptible and the number of recovered individuals. It is able to model some diseases relatively well, but is inaccurate for others and misses out on local spreading and effects. Hence a networked SIR model was proposed, where instead of full mixing between individuals, infected individuals can now only infect its neighbours in the graph/network, which typically represents some form of “close contact”.
The networked SIR model works as follows.
At each timestep, each susceptible individual can be infected by one of its infected neighbours (doesn’t matter which one, as an individual is infected regardless of who caused it). Each infected neighbour has a chance to infect the susceptible individual. This chance is typically modelled as an infection parameter α - for each chance, there is α probability of infection. In addition, at each timestep each infected individual have a chance of recovering, either naturally or from medicine and other means (this model doesn’t care which means). Let the recovery parameter β represent this, which means there is β probability that an infected individual will recover and change to recovered state. There is no transition for susceptible to recovered (which could be interesting, e.g., to model vaccination, but left for future assignments).
As you can probably infer, the more neighbours one has, the higher potential for infection. Hence one reason for the general advice from the health departments to reduce the number of close contacts. Also wearing masks reduces the infection probability, again reducing the spread of an outbreak. In this assignment, you will get an opportunity to experiment with these parameters and see what differences they make.
For more information about SIR and epidemic modelling, have an initial read here https://en.wikipedia.org/wiki/Compartmental_models_in_epidemiology. We will also release some recordings talking more about the model on Canvas, particularly providing more details about how to run the SIR model to simulate an epidemic, please look at those also when they become available.
Incidence Matrix Representation
The incidence matrix represents a graph as a set of vertices and list of edges incident to each vertex as a 2D array/matrix. More formally, let the incidence matrix of a undirected graph be an n x m matrix A with n and m are the number of vertices and edges of the graph respectively. The values in the matrix A follows the following rules:
Each edge ek is represented by a column in A.
Each vertex is represented by a row in A.
Let the two incident vertices to an edge ek be vi and vj. Then the matrix entries Ai,k and Aj,k are both = 1.
Ai,k = 0 for all other non-incident edges.
For example, the following graph:
For further readings about this graph representation, please see https://en.wikipedia. org/wiki/Incidence_matrix.
Assignment Details
The assignment is broken up into a number of tasks, to help you progressively complete the project.
Task A: Implement the Graph Representations, their Operations and the Networked SIR model.
In this task, you will implement data structures for representing undirected, unweighted graphs using the adjacency list, adjacency matrix and incidence matrix representations. Your implementation should also model vertices that have SIR model states associated with them. Your implementation should support the following operations:
Create an empty undirected graph (implemented as a constructor that takes zero arguments).
Add a vertex to the graph.
Add an edge to the graph.
Toggle the SIR state on vertices.
Delete a vertex from the graph.
Delete an edge from the graph.
Compute the k hop neighbours of a vertex in the graph.
Print out the set of vertices and their SIR states.
Print out the set of edges.
In addition, we want you to implement the (networked) SIR epidemic model to simulate how a virus can spread through a population.
Note that you are welcome to implement additional functionality. When constructing our solutions to the assignment, we have found that adding some methods was helpful, particularly for implementing the SIR model. But the above functionalities are ones you should complete and ones you will be assessed on.
Data Structure Details
Graphs can be implemented using a number of data structures. You are to implement the graph abstract data type using the following data structures:
Adjacency list, using an array of linked lists.
Adjacency matrix, using a 2D array (an array of arrays).
Incidence matrix, using a 2D array (an array of arrays).
For the above data structures, you must program your own implementation, and not use the LinkedList or Matrix type of data structures in java.utils or any other libraries. You must implement your own nodes and methods to handle the operations. If you use java.utils or other implementation from libraries, this will be considered as an invalid implementation and attract 0 marks for that data structure. The only exceptions are:
if you choose to implement a map of vertex labels to a row or column index for the adjacency matrix or incidence matrix, you may use one of the existing Map classes to do this.
if you choose to implement a map of vertex labels to its associated SIR state, you may use of the existing Map classes to do so.
Operations Details
Operations to perform on the implemented graph abstract data type are specified on the command line. They are in the following format:
<operation> [arguments]
where operation is one of {AV, AE, TV, DV, KN, PV, PE, SIR, Q} and arguments is for optional arguments of some of the operations. The operations take the following form:
AV
<iteration number> : [<space separated, list of newly infected
vertices>] : [<space separated, list of newly recovered vertices>]
Testing Framework
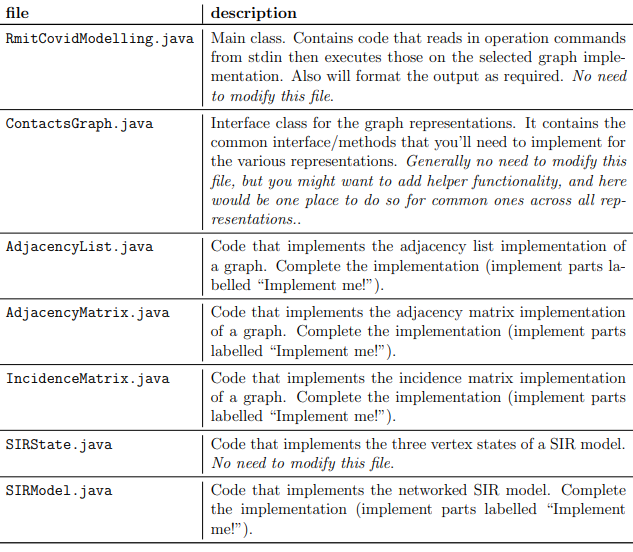
We provide Java skeleton code (see Table 1 for the important files) to help you get started and automate the correctness testing. You may add your own Java files to your final submission, but please ensure that they compile and can be run on the core teaching servers.
Notes
Consider the specifications here carefully. If you correctly implement the “Implement me!” parts and follow the output formating for operations like PV, PE and SIR, you in fact do not need to do anything else to get the correct output formatting. The main class in the provided skeleton code will handle this.
The implementation details are up to you, but you must implement your own data structures and algorithms, i.e., do not use the built-in structures in Java unless for the purposes outlined in the box above.
If you develop on your own machines, please ensure your code compiles and runs on the university’s core teaching servers. You don’t want to find out last minute that your code doesn’t compile on these machines. If your code doesn’t run on these machines, we unfortunately do not have the resources to debug each one and cannot award marks for testing.
Students succeed in their courses by connecting and communicating with an expert until they receive help on their questions

Consult our trusted tutors.








 Login | Sign Up
Login | Sign Up

