1. Loss Functions for Linear Regression:
Assume that the hypothesis function is f(w, b, x) = w T x + b. In the standard linear regression case, given an instance xi, yi on the training set, the loss function is defined as Li(w, b) = [f(w, b, xi) − yi ] 2 . Imagine that we are still interested in posing the optimization problem (over the dataset) as:
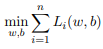
What if we were to use some slightly different loss functions? Can you answer if the following loss functions make sense?
(a) Li(w, b) = [f(w, b, xi) − yi ] 3
(b) Li(w, b) = [f(w, b, xi) − yi ] 4
(c) Li(w, b) = exp[f(w, b, xi) − yi ]
(d) Li(w, b) = max(0, −yif(w, b, xi))
Part 1: Please answer exactly why these loss functions may or may not be a good choice for regression.
Part 2: Also, compute the gradients of the loss function in each of the cases above.
Part 3: Wherever the loss function makes sense, can you answer how the resulting solution
will be different from the standard squared loss? what are the pros and cons of these loss functions
compared to the squared loss.
Students succeed in their courses by connecting and communicating with an expert until they receive help on their questions

Consult our trusted tutors.








 Login | Sign Up
Login | Sign Up

