Task 3: Indexing Bag of Words data
In this task you are asked to create a partitioned index of words to documents that contain the words. Using this index you can search for all the documents that contain a particular word efficiently.
The data is supplied with the assignment at the following locations3:
Small version Full version
Task_3/Data/docword-small.txt Task_3/Data/docword.txt
Task_3/Data/vocab-small.txt Task_3/Data/vocab.txt
The first file is called docword.txt, which contains the contents of all the documents stored in the following format:
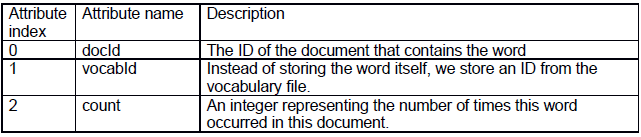
The second file called vocab.txt contains each word in the vocabulary, which is indexed by vocabIndex from the docword.txt file.
Here is a small example content of the docword.txt file.
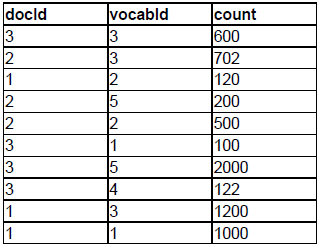
Here is an example of the vocab.txt file
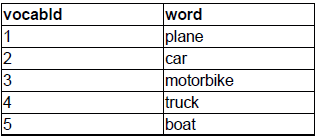
Complete the following subtasks using Spark:
a) [spark SQL] Calculate the total count of each word across all documents. List the words in ascending alphabetical order. Write the results to “Task_3a-out” in CSV format (multiple output parts are allowed). So, for the above small example input the output would be the following:
boat,2200
car,620
motorbike,2502
plane,1100
truck,122
Note: spark SQL will give the output in multiple files. You should ensure that the data is sorted globally across all the files (parts). So, all words in part 0, will be alphabetically before the words in part 1.
b) [spark SQL] Create a dataframe containing rows with four fields: (word, docId, count, firstLetter). You should add the firstLetter column by using a UDF which extracts the first letter of word as a String. Save the results in parquet format partitioned by firstLetter to docwordIndexFilename. Use show() to print the first 10 rows of the dataframe that you saved.
So, for the above example input, you should see the following output (the exact ordering is not important):
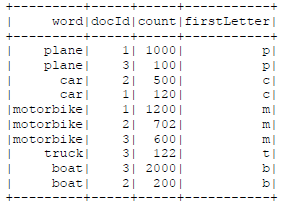
c) [spark SQL] Load the previously created dataframe stored in parquet format from subtask b). For each document ID in the docIds list (which is provided as a function argument for you), use println to display the following: the document ID, the word with the most occurrences in that document (you can break ties arbitrarily), and the number of occurrences of that word in the document. Skip any document IDs that aren’t found in the dataset. Use an optimisation to prevent loading the parquet file into memory multiple times. If docIds contains “2” and “3”, then the output for the example dataset would be:
For this subtask specify the document ids as arguments to the script. For example:
$ bash build_and_run.sh 2 3
d) [spark SQL] Load the previously created dataframe stored in parquet format from subtask b). For each word in the queryWords list (which is provided as a function argument for you), use println to display the docId with the most occurrences of that word (you can break ties arbitrarily). Use an optimisation based on how the data is partitioned.
If queryWords contains “car” and “truck”, then the output for the example dataset would be:
[car,2]
[truck,3]
For this subtask you can specify the query words as arguments to the script. For example:
$ bash build_and_run.sh computer environment power
Students succeed in their courses by connecting and communicating with an expert until they receive help on their questions

Consult our trusted tutors.








 Login | Sign Up
Login | Sign Up

