2. Bag of words and single topic model
We consider a classification problem where we want to predict the topic of a document from a given corpus (collection of documents). The topic of each document can either be sports or politics. 2/3 of the documents in the corpus are about sports and 1/3 are about politics.
We will use a very simple model where we ignore the order of the words appearing in a document and we assume that words in a document are independent from one another given the topic of the document.
In addition, we will use very simple statistics of each document as features: the probabilities that a word chosen randomly in the document is either “goal”, “kick”, “congress”, “vote”, or any another word (denoted by other). We will call these five categories the vocabulary or dictionary for the documents: V = {“goal”, “kick”, “congress”, “vote”, other}.
Consider the following distributions over words in the vocabulary given a particular topic:
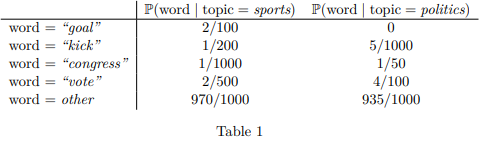
This table tells us for example that the probability that a word chosen at random in a document is “vote” is only 2/500 if the topic of the document is sport, but it is 4/100 if the topic is politics.
(a) What is the probability that a random word in a document is “goal” given that the topic is politics?
(b) In expectation, how many times will the word “goal” appear in a document containing whose topic is sports?
(c) We draw randomly a document from the corpus. What is the probability that a random word of this document is “goal”?
(d) Suppose that we draw a random word from a document and this word is “kick”. What is the probability that the topic of the document is sports?
(e) Suppose that we randomly draw two words from a document and the first one is “kick”. What is the probability that the second word is “goal”?
(f) Going back to learning, suppose that you do not know the conditional probabilities given a topic or the probability of each topic
(i.e. you don’t have access to the information in table 1 or the
topic distribution), but you have a dataset of N documents where
each document is labeled with one of the topics sports and politics. How would you estimate the conditional probabilities (e.g.,
P(word = “goal” | topic = politics)) and topic probabilities (e.g.,
P(topic = politics)) from this dataset?
Students succeed in their courses by connecting and communicating with an expert until they receive help on their questions

Consult our trusted tutors.








 Login | Sign Up
Login | Sign Up

